
Panel data econometrics has gained prominence due to its ability to analyze datasets that have both cross-sectional and time-series dimensions. This dual nature allows economists and researchers to explore how variables change over time across different entities, making it a powerful tool for economic forecasting, policy evaluation, and identifying complex relationships in data. In this post, we will dive deep into what panel data is, how to analyze it using fixed effects and random effects models, and walk through a real-world economic application, all while emphasizing the nuances of model selection.
What is Panel Data in Econometrics?
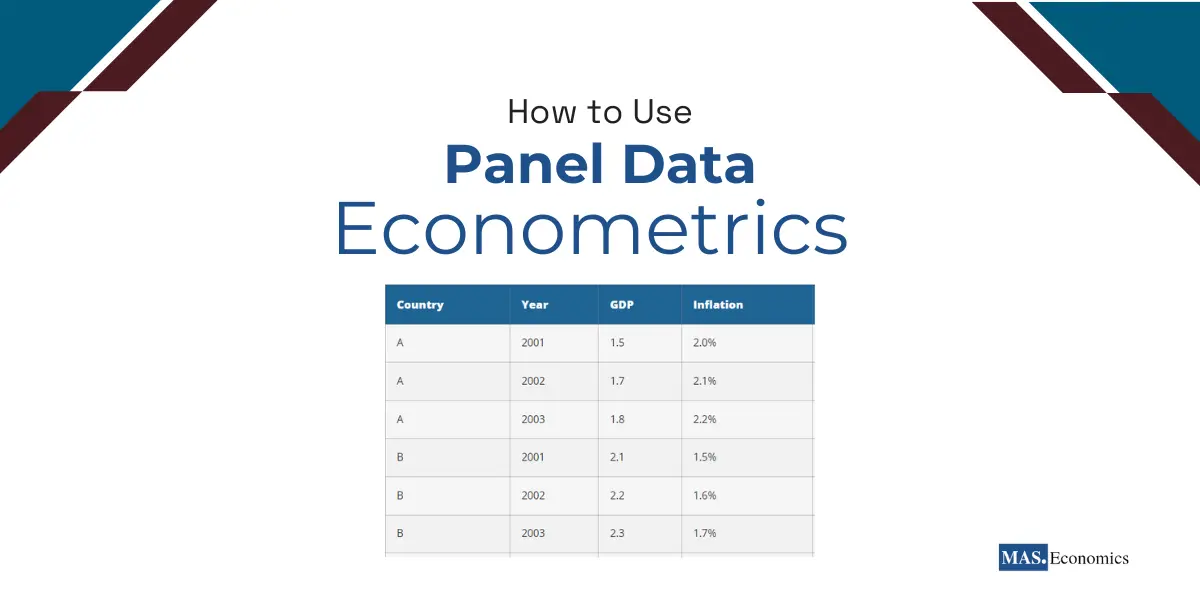
Panel data refers to datasets that observe multiple entities (e.g., individuals, firms, countries) over time, providing repeated measurements across various time periods. This structure combines the benefits of cross-sectional data, which captures variations across entities, and time-series data, which tracks changes over time. For example, panel data could include annual GDP, inflation, and employment rates for a set of countries over a 20-year period.
Econometric models that analyze panel data are designed to account for variations across both entities and time, making them ideal for studying dynamic economic relationships. This combination allows researchers to:
- Control for individual heterogeneity: By accounting for differences between entities, panel data helps to isolate the true impact of variables.
- Identify and analyze dynamics over time: Panel data captures temporal changes, enabling the study of how relationships evolve.
- Improve estimation efficiency: The larger number of observations in panel data leads to more efficient and robust estimates.
For economists, panel data is invaluable for analyzing behaviors that change over time, such as how economic policies affect countries differently or how household income changes with policy shifts.
Understanding Cross-Sectional Data
Cross-sectional data represents observations across different entities at a single point in time. For example, consider GDP, inflation, and employment data for three countries (A, B, and C) in a single year, say 2001:
| Country | Year | GDP | Inflation | Employment |
|---|---|---|---|---|
| A | 2001 | 1.5 | 2.0% | 55% |
| B | 2001 | 2.1 | 1.5% | 65% |
| C | 2001 | 1.2 | 2.5% | 45% |
This table shows how cross-sectional data looks—different entities (countries) are observed at a single point in time (2001). It helps us compare the economic metrics across countries but doesn’t show how these metrics change over time.
Understanding Time-Series Data
Time-series data tracks changes for a single entity over different time periods. For example, let’s look at the GDP data for Country A over three years:
| Country | Year | GDP |
|---|---|---|
| A | 2001 | 1.5 |
| A | 2002 | 1.7 |
| A | 2003 | 1.8 |
|
||
This table illustrates time-series data, where one entity (Country A) is tracked over multiple time periods (2001-2003). It helps us see how the GDP of Country A changes over time but doesn’t allow for a comparison with other countries in the same years.
Combining Cross-Sectional and Time-Series Data to Form Panel Data
Panel data combines the features of cross-sectional data (observations across multiple entities) and time-series data (observations over multiple time periods) into one dataset. For instance, let’s consider a dataset with three countries (A, B, and C) observed over three years:
| Country | Year | GDP | Inflation | Employment |
|---|---|---|---|---|
| A | 2001 | 1.5 | 2.0% | 55% |
| A | 2002 | 1.7 | 2.1% | 56% |
| A | 2003 | 1.8 | 2.2% | 57% |
| B | 2001 | 2.1 | 1.5% | 65% |
| B | 2002 | 2.2 | 1.6% | 66% |
| B | 2003 | 2.3 | 1.7% | 67% |
| C | 2001 | 1.2 | 2.5% | 45% |
| C | 2002 | 1.3 | 2.6% | 46% |
| C | 2003 | 1.4 | 2.4% | 47% |
|
|
||||
This structure allows researchers to analyze how each country’s GDP, inflation, and employment change over time and compare these changes across different countries during the same periods.
Why It’s Called Longitudinal Data
Panel data is often referred to as longitudinal data because it involves observing the same entities over time. This longitudinal aspect allows us to track the “long-term” effects or changes within each entity, such as how GDP or employment evolves in Country A over several years. It also allows for comparisons between entities, like Country A and Country B, in each year.
Longitudinal Data captures both:
- Within-entity variations: How a specific entity changes over time (e.g., Country A’s GDP growth).
- Between-entity variations: How different entities compare at specific points in time (e.g., comparing GDP between Country A and Country B in 2001).
Fixed Effects vs. Random Effects Models
Two of the most commonly used econometric models for analyzing panel data are fixed effects and random effects models. Understanding the differences between these models is critical in deciding how to analyze panel data correctly.
Fixed Effects Model
The fixed effects (FE) model controls for individual-specific characteristics that may influence the dependent variable but remain constant over time. In the FE model, each entity has its own intercept, allowing for entity-specific variability.
The general form of a fixed effects model is:
[
Y_{it} = alpha_i + beta X_{it} + u_{it}
]
Explanation:
- Yit: Dependent variable for entity i at time t.
- αi: Individual-specific intercept for entity i, controlling for time-invariant characteristics.
- Xit: Explanatory variables.
- β: Coefficient of the explanatory variable.
- uit: Error term.
When to Use the Fixed Effects Model:
- Focus on time-varying variables: The FE model is ideal when the main interest is analyzing the impact of variables that change over time within entities.
- Presence of omitted variable bias: If there are unobserved characteristics that vary between entities but are constant over time, the FE model helps control for these factors.
Advantages:
- Controls for all time-invariant characteristics of entities, reducing bias.
- Allows for more accurate estimates of the effect of time-varying variables.
Random Effects Model
The random effects (RE) model, on the other hand, assumes that the differences across entities are random and uncorrelated with the independent variables in the model. Instead of allowing each entity its own intercept, RE treats these differences as part of the error term.
The general form of a random effects model is:
[
Y_{it} = alpha + beta X_{it} + u_{it} + epsilon_i
]
Explanation:
- Yit: Dependent variable for entity i at time t.
- α: Overall intercept.
- εi: Random effects that are specific to each entity.
- Other terms are as defined above.
When to Use the Random Effects Model:
- Inclusion of time-invariant variables: If you need to include variables that do not change over time (e.g., geographic location), RE allows these to be included as explanatory variables.
- Assumption of no correlation: The RE model is appropriate when the unique errors (ϵiepsilon_iϵi) are uncorrelated with the explanatory variables.
Advantages:
- More efficient than FE if the assumption of no correlation holds.
- Allows for a broader analysis by including time-invariant variables.
Choosing Between Fixed and Random Effects with the Hausman Test
Deciding between fixed effects and random effects models is often guided by the Hausman test, which tests whether the unique errors (ϵiepsilon_iϵi) are correlated with the regressors.
- If the Hausman test rejects the null hypothesis: Use the fixed effects model, as it indicates that the entity-specific effects are correlated with the independent variables.
- If the Hausman test fails to reject the null hypothesis: The random effects model is more efficient and can be used.
The Hausman test is a crucial step in panel data analysis, as choosing the wrong model can lead to biased or inefficient estimates.
Real-World Example: Analyzing Economic Growth Using Panel Data
Consider a dataset that examines the impact of trade openness and inflation on economic growth across 50 countries over a 10-year period. Our goal is to determine how these variables influence GDP growth, while accounting for country-specific characteristics.
Step-by-Step Panel Data Analysis
Prepare the Data:
Ensure that the dataset has both cross-sectional (countries) and time-series (years) dimensions. Clean the data to address missing values and ensure consistency across observations.
Conduct a Pooled OLS Regression:
Start with a pooled ordinary least squares (OLS) regression to understand the relationships without accounting for entity-specific effects:
[
GDP_{it} = alpha + beta_1 text{TradeOpen}_{it} + beta_2 text{Inflation}_{it} + u_{it}
]
Run the fixed effects model to account for country-specific characteristics:
[
GDP_{it} = alpha_i + beta_1 text{TradeOpen}_{it} + beta_2 text{Inflation}_{it} + u_{it}
]
Each country gets its own intercept ((alpha_i)), controlling for unobservable characteristics like geographic factors or cultural differences.
Estimate the Random Effects Model:
Run the random effects model to see if treating country-specific effects as random is appropriate:
[
GDP_{it} = alpha + beta_1 text{TradeOpen}_{it} + beta_2 text{Inflation}_{it} + epsilon_i + u_{it}
]
Perform the Hausman Test:
Compare the fixed and random effects models using the Hausman test. If the test statistic is significant, use the fixed effects model.
Interpret the Results:
Depending on the model selected, interpret the coefficients to understand how trade openness and inflation impact GDP growth across different countries. Analyze whether the variables show significant effects and the direction of these relationships.
Limitations of Panel Data Analysis and Solutions
While panel data offers rich analytical opportunities, it comes with challenges:
Missing Data
Panel datasets often have gaps due to missing observations. Imputation techniques, like mean imputation or regression-based imputation, can help address this issue.
Autocorrelation
Since panel data involves time-series observations, autocorrelation can affect the results. Using robust standard errors or models like dynamic panel data (e.g., GMM) can mitigate this problem.
Multicollinearity
The inclusion of many explanatory variables can lead to multicollinearity. Address this by removing highly correlated variables or using dimensionality reduction techniques like PCA.
Conclusion
Panel data provides a versatile and comprehensive framework for analyzing datasets that include both cross-sectional and time-series dimensions. By allowing for individual-specific effects and capturing changes over time, it is particularly useful for understanding dynamic relationships in economics. The choice between fixed effects and random effects models is crucial, and the Hausman test offers a methodical way to determine the best fit for your analysis. Addressing challenges such as missing data, autocorrelation, and multicollinearity ensures that the resulting models are accurate and reliable.
Thanks for reading! If you found this helpful, share it with friends and spread the knowledge.
Happy learning with MASEconomics







{kind=link}